")
Com o lançamento dos novos processadores Intel Core Ultra 200 e 200V, a Intel também atualizou a arquitetura de núcleos P, de desempenho. No lugar dos Raptor Cove e Redwood Cove, dos chips Raptor Lake (Refresh) e Meteor Lake, respectivamente, a empresa introduziu os novos Lion Cove, com uma série de mudanças profundas tanto de design quanto de funcionamento.
A nova arquitetura de núcleos foi totalmente redesenhada, modificando inclusive a presença ou não hyperthreading nos núcleos físicos, constante nos produtos da empresa desde 2002 com os primeiros Xeon.
Durante a semana anterior à Computex 2024, o Canaltech participou do Intel Tech Tour, também em Taiwan. No evento fechado para a imprensa especializada, a empresa apresentou detalhes sobre os novos núcleos Lion Cove, bem como os impactos das mudanças para os novos produtos Intel Core Ultra 200 e futuras gerações de processadores.
Separação do CPU Scheduler (Escalonador de CPU)
O CPU Scheduler — ou escalonador da CPU — é o componente responsável por selecionar processos na memória que estejam prontos para serem executados e os aloca na “fila de execução” da CPU. A primeira e maior mudança nos novos núcleos Lion Cove é a separação do Escalonador Matemático Unificado em um Escalonador Integral e um Escalonador Vetorial.

Quais os benefícios dessa separação?
O primeiro benefício da mudança é a melhor eficiência energética, decorrente da capacidade de controlar melhor o escalonador. Por exemplo, se não houver código vetorial em execução, o escalonador vetorial pode ser desativado para reduzir o consumo total de energia ou realocar essa energia para outras partes do núcleo, potencialmente permitindo que outras partes do núcleo operem em frequências mais altas.

A segunda grande vantagem em dividir o escalonador é simplificar a operação do projeto total. Com um escalonador unificado de 5 portas lógicas, todas essas portas precisam lidar com instruções integrais, de 2 operandos e vetoriais, de 3 operandos, significa que você precisa ter um total de 15 portas.
Além disso, ele também precisa ter suporte a mascaramento, método que define a exibição ou ocultamento de dados dependendo do processo lógico. Sendo assim, dependendo do processo, um escalonador unificado precisaria lidar com quase 20 operandos simultaneamente, reduzindo sua eficiência.
Ao dividir em dois escalonadores, é possível reduzir o escalonador vetorial para um projeto de 4 portas de 3 operandos — até 12 simultâneos — e mascaramento, e um integral de 6 portas para apenas 2 operandos, também de até 12 simultâneos. Com isso, as filas de execução de instruções são otimizadas, eliminando a necessidade de ocupar escalonadores robustos para tarefas simples.
Mudança na hierarquia do cache
Outra mudança nos núcleos Lion Cove é a introdução de um nível intermediário de memória cache, acompanhado da renomeação de uma das camadas de memória de baixo nível. O que até então era chamado de Cache L1, com latência de 4 ciclos computacionais e volume de 48 KB, agora passa a se chamar L0.
A nova cache L1 é um pouco mais lenta, com latência de 9 ciclos computacionais, mas relativamente maior, com 192 KB de capacidade. Ela irá servir como uma memória de buffer entre as novas cache L0, ainda extremamente rápidas, e as já conhecidas cache L2, maiores (3 MB), porém consideravelmente mais lentas, com latência de 17 ciclos.

Assim como todo o projeto dos novos processadores, a intenção é diluir eventuais gargalos de desempenho entre componentes em camadas intermediárias de hardware. Elas servem como estágios transitórios da informação, permitindo acesso mais rápido a instruções prioritárias sem precisar acelerar todo o conjunto do núcleo, reduzindo perdas de energia e, consequentemente, o aquecimento.
Hyperthreading opcional
A mudança mais impactante nos núcleos Lion Cove é a presença opcional de hyperthreading. A funcionalidade está nos chips Intel desde 2002, começou ter menos ênfase a partir de 2022 com os processadores Alder Lake, que introduziram arquitetura desagregada, trazendo núcleos de desempenho (P) e núcleos de eficiência (E), com e sem hyperthreading, respectivamente.
O hyperthreading permite que um mesmo núcleo trabalhe com duas linhas paralelas de execução de instruções, ou threads. Por mais que isso permita otimizar o pipelining das instruções, a tecnologia fazia mais sentido quando cada processador contava com apenas um tipo de núcleo.
A partir dos Intel Core de 12?ª geração, o pipelining dos núcleos P muitas vezes acaba subutilizado. Muitas das cadeias de instruções que rodavam nos threads adicionais estavam relacionadas a processos constantes e mais leves do sistema, e passaram a ser direcionadas para os núcleos de eficiência.
Ainda que isso desafogue threads dos núcleos P para tarefas exigentes, são raríssimos os programas em PCs domésticos que se beneficiam desse recurso excedente. Inclusive, essa é uma das principais razões que games costumam performar melhor em CPUs com frequências mais elevadas, mesmo que com menos threads.
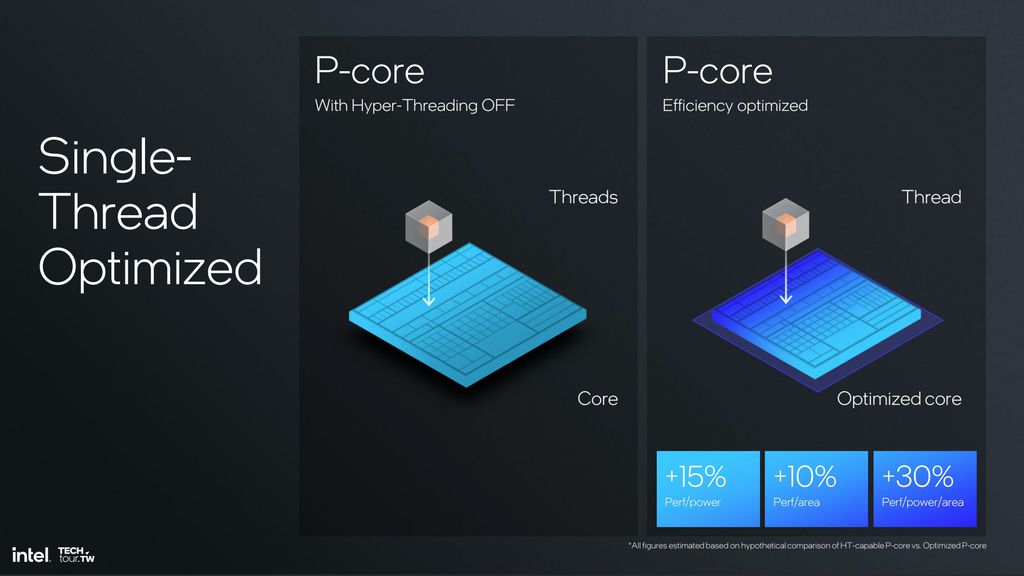
Lunar Lake sem Hyperthreading
Cada tipo de código tem um limite de ganho de desempenho por número de threads, calculado pela Lei de Amdahl. Ao que tudo indica, desde a chegada dos núcleos híbridos, essa conta começou a fazer cada vez menos sentido para alguns mercados, e a partir dos núcleos Lion Cove, apenas linhas selecionadas de processadores vão manter o hyperthreading.
Os chips Lunar Lake, para sistemas móveis como IA PCs, são a primeira geração Intel em 20 anos a eliminar o hyperthreading. Considerando que eles também contam com os novos núcleos Skymont, de eficiência, e NPUs, remover os threads adicionais dos Lion Cove viabiliza entregar menor consumo de energia, frequências mais elevadas e até 10% mais desempenho por área do núcleo.
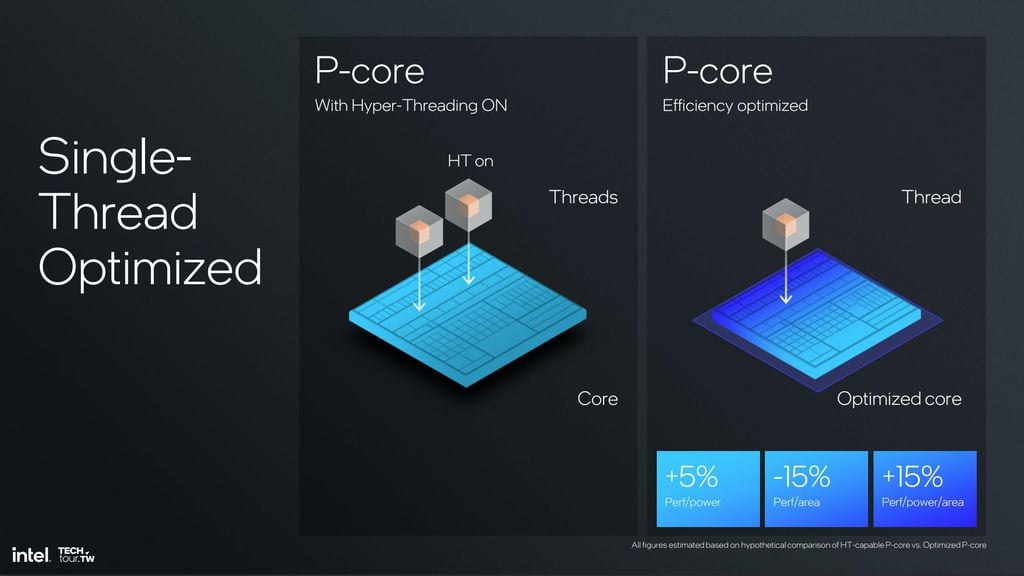
Arrow Lake com Hyperthreading
Já nos processadores Arrow Lake, voltados para desktop, o sistema tem muito menos restrições de energia e dissipação térmica. Dessa forma, não é preciso se preocupar tanto em entregar um processador de consumo tão reduzido, sendo possível manter o hyperthreading para tirar o máximo de desempenho do processador.
Por que isso não foi feito antes?
A maior limitação na produção de chips está no processo de fabricação, que envolve impressões extremamente delicadas de circuitos por meio de processos de irradiação, a microlitografia. Até então, cada arquitetura Intel utiliza uma abordagem de agregamento de pastilhas apelidado de “Mar de FUBS” (Functional Unit Block/ Blocos de Unidades Funcionais).

Contudo, a partir dos Lunar Lake e Arrow Lake, a precisão das lentes utilizadas no novo processo de microlitografia possibilitou aumentar a modularidade do nível de FUBs, para o de células lógicas menores. O novo processo, batizado de “Mar de Células”, garante que mesmo em arquiteturas essencialmente idênticas, seja possível personalizar componentes específicos, redesenhando apenas os wafers que sejam estritamente necessários, viabilizando, por exemplo, núcleos Lion Cove com e sem hyperthreading dependendo do projeto.
Mais desempenho e potencial de modularidade
Até os processadores Meteor Lake, os núcleos de desempenho conseguiam realizar apenas uma multiplicação integral por ciclo computacional. Com a nova arquitetura, além da criação de um escalonador integral dedicado, a Intel também acrescentou uma Unidades Lógicas Aritmética (ALU) adicional aos componentes de execução integral, passando de 5 para 6.
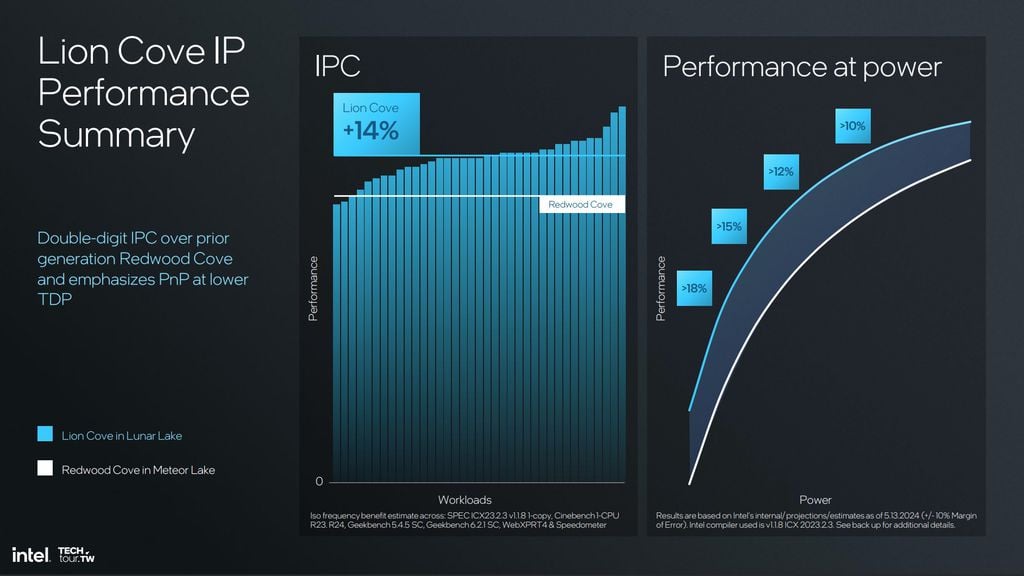
Essa combinação permite aos novos núcleos realizarem até 3 operações integrais por ciclo computacional, o que se traduz na prática como muito mais poder computacional bruto. Em termos gerais, apenas os núcleos Lion Cove entregam 14% mais desempenho sobre os Redwood Cove da primeira geração Intel Core Ultra, sem considerar o restante de melhorias do conjunto da CPU.
No entanto, o bom salto geracional de desempenho é mais uma consequência do que a motivação para o desenvolvimento dos novos núcleos. O maior benefício do projeto dos núcleos Lion Cove é entregar uma estrutura de die de silício ainda mais desagregada do que a Intel já vinha fazendo, ampliando a granularidade e modularidade do processador.

Quanto mais componentes individualizados no CPU, mais fácil é identificar as fraquezas em cada geração e atacar apenas os pontos que geram gargalos em potencial. Com isso, a Intel consegue direcionar os investimentos de P&D, diluindo custos e resultando em avanços mais rápidos e eficientes entre gerações, com a possibilidade inclusive de criar produtos sob medida para mercados específicos, como workstations ultrafinas ou consoles portáteis.
- Compre notebook gamer com CPU Intel Core pelo melhor preço!
- Compre processador Intel Core pelo melhor preço!